Abstract:本文讲了聚类和降维两种无监督学习方法。聚类是对无标记数据分析结构并分类的划分算法。降维是减少数据集的特征变量,一般通过PCA算法实现,有数据压缩和可视化数据的作用。
聚类cluster
Abstract:聚类是一种无监督学习方法,我们要从无标记的数据中学习,聚类是对无标记数据分析结构并分类的划分算法。几个典型应用实例是市场分析、社交网络分析、组织运算集群和星系数据分析等。K-Means(K均值)算法是目前应用最广泛的聚类算法,通过随机选取K个点作为聚类中心,反腐进行簇分配和移动聚类中心的方式来实现分类。K均值优化目标函数将帮助我们找到更好的簇,并且避免局部最优解。K均值算法的原理就是最小化代价函数J的过程。随机初始化聚类中心:初始化K均值很多次,并运行K均值方法很多次,通过多次尝试来保证我们最终能得到一个足够好的结果,一个尽可能局部或全局最优的结果。关于聚类数量的选取:肘部法则可帮助确定聚类数量,但不能保证总是表现的好;通过下游(应用目的)来决定聚类数量。大部分时候聚类数目是人工输入决定。选择聚类数目的更好方法是去问一下你运行K-均值聚类是为了什么目的?然后想一想聚类的数目是多少才适合你运行K-均值聚类的后续目的。
无监督学习算法与监督学习算法对比
监督学习:将有标记的数据分类。如:这是一组附有标记的训练数据集,我们想要找出一个决策边界,来将两者分开。并针对一组标记的训练数据提出一个适当的假设函数来拟合训练样本,以便更好地预测未来。

无监督学习:面对的是一组无标记的训练数据,数据之间不具任何关联的标记。要求算法对无标记数据分析结构并分类。其中一种可能的结构是所有的数据大致地划分成两个类(或组),这种划分的算法称为聚类算法。

聚类
聚类是对无标记数据分析结构并分类的划分算法。
应用实例:

- 图1是细分市场,将所有用户划分至不同的细分市场组,以便于营销或服务。
- 图2是社交分析体系,比如在社交网络中观察一群人,看他们和谁有电子邮件来往,或者查找一群相互有联系的人。
- 图3是用聚类来组织运算集群或组织数据中心,因为,如果你知道在集群中,哪些计算机的数据中心倾向于一起工作,你可以用它重新组织你的资源,网络的布局,以及数据中心和通信。
- 图4是使用聚类算法来试图理解星系的形成,和其中的天文细节。
K-Means算法
在聚类问题中,我们有未加标签的数据。我们希望有一个算法能够自动的把这些数据分成有紧密关系的子集,或是簇。K均值 (K-means)算法是现在最为广泛使用的聚类方法。

如上图,有一些没加标签的数据,随机选择2个点,为聚类中心。2个点即聚成2个类。
K均值是一个迭代方法,它要做成2件事情:
- 簇分配
- 移动聚类中心
K-Means 第一步:簇分配
遍历样本,根据相对距离来分成两类:在K均值算法的每次循环中,第一步是要进行簇分配。这就是说,我要遍历所有的样本(就是图上所有的绿色的点),对数据集中的所有点,依据他们更接近红色这个中心、还是蓝色这个中心,进行染色。染色后:

K-Means 第二步:移动聚类中心
移动2个聚类中心到和它颜色相同的那堆点的均值处:找出所有红色的点,计算出它们的均值位置,然后我们就把红色点的聚类中心移动到这里。对蓝色的点也同样计算平均位置,然后移动蓝色聚类中心到该平均位置处。

K-Means 第三步:重复执行上面两步
然后我们就会进入下一个簇分配。我们重新检查所有没有标签的样本,依据它离红色中心还是蓝色中心更近一些,重新将它染成红色或是蓝色。然后我们再次移动聚类中心。计算蓝色点的均值,以及红色点的均值,然后移动两个聚类中心。然后再做一遍簇分配和移动聚类中心操作。实际上,如果你从这一步开始,一直迭代下去,聚类中心是不会变的;并且 那些点的颜色也不会变。在这时,我们就能说K均值方法已经收敛了。
K-Means的规范化描述
K均值算法接受2个输入:
- 第一个是参数K,表示你想从数据中聚类出簇的个数
- 第二个输入参数是训练集{x(1),x(2),…,x(m)}
因为这是非监督学习,我们的数据集中不需要yy,同时在非监督学习的 K均值算法里,我们约定x(i)x(i)是一个nn维向量,这就是“训练样本是nn维而不是n+1n+1维”的原因(按照惯例,排除x0=1x0=1这一项)。
K均值算法:

1.随机初始化K个聚类中心,记作μ1,μ2一直到μK。
2.K均值内部循环执行以下步骤:
- 簇分配
首先对于每个训练样本,我们用变量c(i)表示K个聚类中心中最接近x(i)的那个中心的下标(具体的类别),这就是簇分配。
大写的K表示所有聚类中心的个数,小写的k则表示某个聚类中心的下标。
在所有K个中心中,找到一个k使得xi到μk的距离是x(i)到所有的聚类中心的距离中最小的那个,这就是计算ci的方法。
- 移动聚类中心:对于每个聚类中心:kk从1循环到KK,将μkμk赋值为这个簇的均值。
某一个聚类中心,比如说是μ2μ2被分配了一些训练样本:1,5,6,10 这个表明c(1)=2, c(5)=2,c(6)=2, c(10)=2。如果我们从簇分配那一步得到了这些结果,这表明,样本1,5,6,10被分配给了聚类中心2;然后在移动聚类中心这一步中,我们计算出这四个的平均值,即计算x(1)+x(5)+x(6)+x(10),然后计算它们的平均值。这时μ2就是一个n维的向量,因为x(1),x(5),x(6),x(10) 都是n维的向量。这样聚类中心μ2的移动就结束了。
异常情况
目的是让μk移动到分配给它的那些点的均值处,那么如果存在一个没有点分配给它的聚类中心,那怎么办?
- 直接移除那个聚类中心,最终将会得到K−1个簇,而不是K个簇。
- 如果就是需要K个簇,尽管存在没有点分配给它的聚类中心,那就重新随机找一个聚类中心。
K均值算法的另一常见应用:应对没有很好分开的簇(non-separated clusters)。
指的是没有很好地隔离开的K个簇,可使用K均值算法进行聚类,如:

上图是一个关于T恤大小的应用例子(根据人们身高体重的样本来分成三类,以做出三种不同大小的T恤):
假设你是T恤制造商,你找到了一些人,想把T恤卖给他们,然后你搜集了一些这些人的身高和体重的数据。我猜,身高体重更重要一些。然后你可能收集到了上图中一些关于人们身高和体重的样本,然后你想确定一下T恤的大小。
假设我们要设计三种不同大小的t恤:小号、中号、和大号,那么小号应该是多大的?中号呢?大号呢?
尽管这些数据原本看起来并没有三个分开的簇,但是从某种程度上讲,K均值仍然能将数据分成几个类。你能做的就是看这第一群人,然后查看他们的身高和体重,试着去设计对这群人来说比较合身的小号衣服;以及设计一个中号的衣服;设计一个大号的衣服。
这就是一种市场细分的例子。当你用K均值方法将你的市场分为三个不同的部分,你就能够区别对待你三类不同的顾客群体,从而更好的适应他们不同的需求。就像大、中、小,三种不同大小的衣服那样。
优化目标
优化目标:在大多数我们已经学到的监督学习算法中(例如线性回归,逻辑回归,以及更多的算法)都有一个优化目标函数,即需要通过算法进行最小化的代价函数。
K均值也有这样一个优化目标函数(或者说是代价函数)。
了解和使用这个K均值的优化目标函数有两方面的目的:
- 帮助我们调试学习算法,确保K均值算法是在正确运行中。
- 帮助我们找到更好的簇,并且避免局部最优解。
当K均值正在运行时,我们将对两组变量进行跟踪:
1.c(i)
- c(i)=表示K个聚类中心中最接近x(i)的那个中心的索引(即当前样本x(i)所归为的那个簇的索引)
2.μk:
- μk=表示第k个簇的聚类中心(μk∈Rn)
K均值中我们用大写K来表示簇的总数,用小写k来表示聚类中心的序号;k∈{1,2,…,K}
还有另一个符号,我们用μc(i):μ(i)c=表示x(i)所属的那个簇的聚类中心
假如说x(i)被划为了第5个簇,这就是说x(i)被分配到了第5个簇,也就是c(i)=5。因此μc(i)=μ5。所以这里的μc(i)就是第5个簇的聚类中心。而也正是我的样本x(i)所属的第5个簇有了这样的符号表示,现在我们就能写出K均值聚类算法的优化目标了。
K均值的代价函数
K均值算法需要最小化的代价函数:J(c(1),…,c(m),μ1,…,μK)=1/m∑i=1/m||x(i)−μ(i)c||^2
代价函数J的参数c(1),…,c(m)以及μ1,…,μK,随着算法的执行过程,这些参数将不断变化。
函数的右边给出了优化目标,即每个样本x(i)到它所属的聚类中心距离的平方值。x(i)就是训练样本的位置,μc(i)是x(i)样本所属的聚类中心的位置。

如上图,x(i)样本被划分到了μ5这个聚类中心,那么||x(i)−μ(i)c||2这个距离的平方,也就是在求样本点x(i)到μ5之间的距离的平方。
K均值的目标就是要最小化代价函数:
minc(1),…,c(m),μ1,…,μKJ(c(1),…,c(m),μ1,…,μK)
总结:K均值算法的原理就是最小化代价函数JJ的过程。我们也可以用这个原理,来调试我们的学习算法,保证我们对K均值算法的实现过程是正确的。
随机初始化
Abstract:初始化K均值聚类方法,如何避开局部最优来构建K均值聚类方法。
随机初始化聚类中心μ1,μ2,…,μK∈R。
1.确保K<m
当运行K均值方法时,你需要有一个聚类中心数值KK,KK值要比训练样本的数量m小,即K<m。
2.随机初始化
随机挑选K个训练样本,然后我要做的是设定μ1,…,μk让它们等于这K个样本。
举例:

随机挑选几个样本,如图中2点作为聚类中心。
此时的这个例子看起来划分的相当不错,但是有时候我可能不会那么幸运。也许我最后会挑选到下面这样的两个点作为聚类中心:

通过对上面两种初始化情况的对比,你可能会猜到K均值算法在它们两种情况下,会得到不同的结果。这取决于聚类簇的随机初始化方法。K均值方法最后可能得到不同的结果,尤其是如果K均值方法落在局部最优的时候。
如果你运行K均值方法,如果它最后得到一个局部最优,这可能是真正的全局最优,你可能会得到这样的聚类结果:

但随机初始化K均值方法也可能会卡在不同的局部最优上面:

对于左边的这种情况,相当于将左下方和上方的样本分为了一类,将右下方的样本分了两类。对于右边的这种情况,相当于将下面的样本整体的分为了一类,将上方的样本分为了两类。
如果你担心K均值方法会遇到上面这种局部最优的问题,并且你想提高K均值方法找到最有可能的聚类的几率的话,我们能做的就是尝试多次随机的初始化,而不是仅仅初始化一次K均值方法就希望它会得到很好的结果。
我们能做的是:初始化K均值很多次,并运行K均值方法很多次,通过多次尝试来保证我们最终能得到一个足够好的结果。一个尽可能局部或全局最优的结果。
选择簇的数量
即确定聚类数目,即如何选择K值。
决定聚类数目最常用的方法:通过看可视化的图,或看聚类算法的输出结果,或其他一些东西来手动决定聚类数目。
大部分情况下,对于数据集中有多少个聚类中心通常是模糊的。实际上,它的真实类别数量的确模糊,并无正确答案,此即无监督学习的特点。

如图,有人看到K=4,有人觉得K=2.
肘部法则 (Elbow Method)
即通过不断改变K值并求出对应代价函数J值,得出一组对应数据,然后画出曲线图,发现曲线像肘部,其中折线转折处很像一个肘点,肘点即我们可选择的K值。
步骤:
1.我们用K值为1来运行K-均值聚类算法。这就意味着所有的数据都会分到一个类里。然后计算代价函数(或者说计算畸变)J,在图中标出;
2.然后我们选用两个聚类来运行K-均值聚类算法。可能用了多个随机的初始中心,也可能没用。那么有两个聚类的话,我们很可能得到一个较小的畸变值,再在图中标出;
3.然后用三个聚类来运行K-均值聚类。你很有可能得到更小的畸变值,标出;
4.之后再让聚类数目等于4、5来运行K-均值聚类,最后我们就能得到一条曲线,它展示了随着聚类数量的增多,畸变值是如何下降的。我们可能会得到一条这样的曲线:

5.在这里,你会发现这样一种模式:K从1变化到2、再从2到3时,畸变值迅速下降;然后在3的时候,到达一个肘点。此后畸变值就下降得非常慢。这样看起来,也许使用3个类是聚类数目的正确选择。这是因为那个点是曲线的肘点。就是说畸变值快速地下降,直到K=3这个点,在这之后就下降得非常慢,那么我们就选K=3。
肘部法则局限性:有时得到的曲线没有清晰的肘点,则用此法选择K值很困难。
通过下游来决定聚类数量
why:通常人们使用K-均值聚类算法是为了某些后面的用途,或者说某种下游的目的。而要求得一些聚类也许你会用K-均值聚类算法来做市场分割。例如我们之前谈论的T恤尺寸的例子,也许你会用K-均值聚类来让电脑的聚类变得更好,或者可能为了某些别的目的学习聚类,等等。如果那个后续下游的目的(比如市场分割)能给你一个评估标准,那么通常来说决定聚类数量的 更好的办法是,看不同的聚类数量能为后续下游的目的提供多好的结果。
(即依据你的应用目的来确定K值)
举例:我需要3种尺寸 or 5种?
情景:选择K=3。我可能有小号、中号、大号三类T恤;K=5,那么我可能有特小号、小号、中号、大号和特大号尺寸的T恤。所以,你可能有3种、4种或者5种T恤尺寸。
K=5时,结果可能如图:

分析:商业盈利角度思考几种尺寸最有利于盈利?我是需要更多的T恤尺寸 来更好地满足我的顾客?还是说我需要更少的T恤尺寸,我制造的T恤尺码就更少,我就可以将它们更便宜地卖给顾客?因此T恤的销售业务的观点 可能会提供给你一个决定采用3个类还是5个类的方法。
降维 (dimensionality reduction)
Abstract:第二种无监督学习问题为降维。我们使用降维的一个主要原因是数据压缩(压缩冗余的特征变量)。数据压缩不仅通过压缩数据使得数据占用更少的计算机内存和硬盘空间,它还能给算法提速。
降维步骤:检查带标签的训练数据集并提取出输入数据,然后应用PCA降维,得到降维厚的数据集,再把已降维的数据集输入到学习算法中得出假设函数,并把降维后的数据作为输入带入,做出预测。
PCA:寻找一组k维向量(一条直线、或者平面、或者诸如此类等等)对数据进行投影,来最小化正交投影误差。
动机
主成分分析(PCA):可数据压缩以加快学习算法,并通过降维可视化复杂数据集。
动机1:数据压缩
数据压缩:
- 通过压缩数据使得数据占用更少的计算机内存和硬盘空间
- 给算法提速。
降维举例:
假设我们有一个有很多很多特征变量的数据集,如上图。假设我们不知道这两个特征变量。其中x1是某个物体的长度,以厘米为单位;另一个x2是它以英寸为单位的长度。所以这是一个非常冗余的数据,与其用两个特征变量x1和x2,它们都是测量到的长度,或许我们应该把这个数据降到一维,只用一个长度的数据。
冗余特征变量的存在:如果你有上百或者上千的特征变量,很容易就会忘记你到底有什么特征变量,而且有时候可能有几个不同的工程师团队。一队工程师可能给你200个特征变量,第二队工程师可能再给你300个特征变量,然后第三队工程师给你500个特征变量。所以你一共有1000个特征变量,这样就很难搞清哪个队给了你什么特征变量。实际上得到这样冗余的特征变量并不难。
所以如果以厘米计的长度被取整到最近的厘米整数,以英寸计的长度被取整到最近的英寸整数。这就是为什么这些样本没有完美地在一条直线上。就是因为取整所造成的误差。
这种情况下,如果我们可以把数据降到一维而不是二维,就可以减少冗余。
降维:减少数据集的特征变量,特征变量数量=维数。
二维降到一维

如图,二维降到一维指:希望找到一条线,基本所有数据都映射到这条线上,以便直接测量这条线上每个样本的位置,称降维后得到的新特征为z1.
实现方式:用一个一维向量(一个数字)z1来表示每个训练样本的位置,这是对原始训练样本的近似。
优点:减少一半的内存需求,加快算法。
三维降到二维

在更典型的降维例子中,我们可能有1000维的数据,我们可能想降低到100维,但是因为这里能可视化的展示数据的维度是有限制的,所以以三维到二维为例。
有一个如上图的数据集,有一个样本x(i)的集合,x(i)是一个三维实数的点,所以我的样本是三维的:x(i)∈R^3
实现方法:把所有的数据,都投影到一个二维的平面内。为了表示一个点在平面上的位置,我们需要两个数来表示平面上一个点的位置。这两个数可能叫做z1和z2。即我们可用一个二维向量z(z1,z2)来表示每一个训练样本。

z(i)∈R^2

如图,3D绘图来重现上面的整个过程。左边是原始数据集,中间是投影到2D的数据集,右边是以z1和z2为坐标轴的2D数据集。因为大部分数据差不多可能都落在某个2D平面上,或者说距离某个2D平面不远。所以我们可以把它们投影到2D平面上。
动机2:可视化数据
对于大多数的机器学习应用,它真的可以帮助我们来开发高效的学习算法,但前提是我们能更好地理解数据。降维就是数据可视化的一种方法。
举例:

如图,假设我们已收集了大量有关全世界不同国家的统计数据集。第一个特征x1是国家的国内生产总值;第二个特征x2是一个百分比,表示人均占有的GDP;第三个特征x3是人类发展指数;第四个特征x4x4是预期寿命;…直到x50。
在这里我们有大量的国家的数据,对于每个国家有50个特征。我们有这样的众多国家的数据集,为了使得我们能更好地来理解数据,我们需要对数据进行可视化展示。这里我们有50个特征,但绘制一幅50维度的图是异常困难的,因此我们需要对数据进行降维,然后再可视化。
实现方式:使用特征向量x(i)来表示每个国家。x(i)有着50个维度。我们需要对这50个特征降维之后,我们可以用另一种方式来代表x(i):使用一个二维的向量zz来代替之前50维的x。

z(i)∈R^2
我们用z1和z2这两个数来总结50个维度的数据,我们可以使用这两个数来绘制出这些国家的二维图,使用这样的方法尝试去理解二维空间下不同国家在不同特征的差异会变得更容易。
降维处理:z1表示象征国家整体情况的特征向量,如”国家总面积”、”国家总体经济水平”;z2表示象征人均情况的特征向量,如“人均GDP”,”人均幸福感”。

降维处理后的维度图如上图。右侧的点,象征着国家整体经济比较好的国家;上方的点,象征着人均经济比较好、人均幸福感较高、人均寿命较长…的国家。
主成分分析法(Principal Componet Analysis, PCA)
Abstract:PCA是降维问题中目前最流行的算法。
首先开始讨论PCA问题的公式描述,也就是说,我们用公式准确地精确地描述:我们想让PCA来做什么。
PCA的执行过程2D -> 1D

情景:有一个二维数据集。
目的:二维降一维。
方法:找到一条直线将数据投影到直线上,而且各样本点到直线的最短距离的平方和必须最小。
PCA:寻找一个低维的面(在这个例子中,其实是一条直线)数据投射在上面,使得这些蓝色小线段的平方和达到最小值。这些蓝色线段的长度被叫做投影误差。【PCA所做的就是寻找一个投影平面,对数据进行投影,使得这个能够最小化。
】
具体阐述PCA:寻找一个向量u(i),该向量属于nn维空间中的向量(在这个例子中是二维的),我们将寻找一个对数据进行投影的方向,使得投影误差能够最小(在这个例子里,我们把PCA寻找到这个向量记做u(1)。所以当我把数据投影到这条向量所在的直线上时,最后我将得到非常小的重建误差。

注:无论PCA给出的是这个u(1)u(1)是正还是负都没关系。因为无论给的是正的还是负的u(1)u(1)它对应的直线都是同一条,也就是我将投影的方向。
attention:PCA被应用前,通常需先进行均值归一化和特征规范化,使得特征x1和x2均值为0,数值在可比较的范围之内。
PCA的执行过程3D -> 2D
PCA:寻找一组k维向量(一条直线、或者平面、或者诸如此类等等)对数据进行投影,来最小化正交投影误差。

如图,寻找两个向量u(1)和u(2),一起定义一个二维平面,并将数据投影到这个二维平面。
PCA和线性回归的关系
PCA与线性回归看起来相似,但其实不同。1.线性回归是最小化点与直线之间的平方误差,而PCA是最小化点与直线的最短距离(直角距离)的平方和误差。2.线性回归有一个特别变量y作为即将预测的值,而PCA没有特殊变量要预测。


如上图1为线性回归,图2为PCA。
PCA算法的实现过程
数据预处理
1.均值归一化(mean normalization)
首先应该计算出每个特征的均值μ,然后我们用x−μ来替换掉x。这样就使得所有特征的均值为0。
举例:
如果x1表示房子的面积,x2表示房屋的卧室数量,然后我们可以把每个特征进行缩放,使其处于同一可比的范围内。
首先计算出每个特征的均值:μj=(1/m)∑(m,i=1)xj(i)
然后每个样本值对应的特征减去其对应的均值:x(i)j←x(i)j−μj
将所有的特征替换为这种形式的结果。这样就保证了所有特征的均值为0。
2.特征缩放(feature scaling)
将每个特征的取值范围都划定在同一范围内,因此对于均值化处理之后的特征值x(i)j−μjxj(i)−μj,我们还需要做进一步处理:x(i)j ← (xj(i)−μj)/sj.
这里sj表示特征j度量范围,即该特征的最大值减去最小值。
PCA算法
PCA是在试图找到一个低维的子空间,然后把原数据投影到子空间上,并且最小化平方投影误差的值(投影误差的平方和,即下图中蓝色线段长度的平方和)。
那么如何计算这个子空间?
1.假如说我们想要把数据从nn维降低到kk维,我们首先要做的是计算出下面这个协方差矩阵(通常用∑来表示):
∑=(1/m)∑(n,i=1)(x(i))*(x(i))^T
这个希腊符号∑∑和求和符号重复了,勿混淆。
2.计算出这个协方差矩阵后,假如我们把它存为Octave中的一个名为Sigma的变量,我们需要做的是计算出Sigma矩阵的特征向量(eigenvectors)。
在Octave中,你可以使用如下命令来实现这一功能:
[U,S,V] = svd(Sigma);
注:svd函数输出3个矩阵USV,我们真正需要的事U矩阵(n*n矩阵),因为U 矩阵的列元素就是我们需要的u(1),u(2)等等

如果我们想将数据的维度从n降低到k的话,我们只需要提取前k列向量。这样我们就得到了u(1)到u(k),也就是我们用来投影数据的k个方向。
取出U矩阵的前k列得到一个新的,由u(1)到u(k)组成的矩阵Ureduce:
(将上图中的n改为k即为Ureduce矩阵,n
*k维)
然后我们用这个Ureduce来对我的数据进行降维。我们定义:z = Ureducex,z∈R^k;其中Ureduce是nk维矩阵,xx 是n×1的矩阵,因此z是k×1的矩阵。
总结PCA全过程:
1.均值归一化 :保证所有的特征量都是均值为0的。
2.特征缩放
3.计算出这个协方差Sigma矩阵
4.应用svd函数来计算出U S V矩阵
[U,S,V] = svd(Sigma);
5.取出U矩阵的前k列元素组成新的Ureduce矩阵
Ureduce = U(:,1:k);
6.z = Ureduce`*x 给出我们从原来的特征xx变成降维后的zz的过程
(三行代码实现PCA)
应用PCA
如何还原数据?
假设有一个已经被压缩过的z(i)它有100个维度,怎样使它回到其最初的表示x(i)也就是压缩前的1000维的数据呢?

如图,在PCA算法中,我们有下面这些样本。我们让这些样本投影在一维平面z1上,并且明确地指定其位置。那么给出一个一维实数点z我们能否,让zz重新变成原来的二维实数点x呢?
即做到:z∈R → x∈R^2.
已知:z=UTreduce*x
若想还原,则方程变为:xapprox=Ureduce*z
检查维度,在这里Ureduce是一个n×k矩阵,z就是一个k×1维向量。将它们相乘得到的就是n×1维。故xapprox是一个n维向量
同时根据PCA的意图,投影的平方误差不能很大。也就是说xapprox将会与最开始用来导出z的原始x很接近。用图表示出来就是这样:

这就是用低维度的特征数据z还原到未被压缩的特征数据的过程。我们找到一个与原始数据xx近似的approx。我们也称这一过程为原始数据的重构(reconstruction)。
选择主成分的数量k
把n维特征变量降维到k维特征变量。这个数字k是PCA算法的一个参数。这个数字k也被称作主成分的数量。
PCA所做的是尽量最小化平均平方映射误差 (Average Squared Projection Error) 。
(1/m)∑(m,i=1)||xi−x(i)approx||^2
即最小化xx和其在低维表面上的映射点之间的距离的平方。这就是平均平方映射误差。
定义数据的总变差(Total Variation):
(1/m)∑(m,1=m)||x(i)||^2
数据的总变差 (Total Variation) 是这些样本的长度的平方的均值。它的意思是 “平均来看,我的训练样本距离零向量(原点)多远?”。
当我们去选择k值的时候,我们通过平均平方映射误差除以数据的总变差来表示数据的变化有多大。我们想要这个比值能够小于1%:
1m∑mi=1||x(i)−x(i)approx||21m∑mi=1||x(i)||2≤0.01
[(1/m)∑(m,i=1)||xi−x(i)approx||^2]/[(1/m)∑(m,1=m)||x(i)||^2] <= 0.01

数字0.01是人们经常用的一个值,另一个常用的值是0.05。如果选择了0.05,就意味着95%的差异性被保留了。从95到99是人们最为常用的取值范围。
你可能会发现,对于许多数据集,即使保留了99%的差异性,可以大幅地降低数据的维度。因为大部分现实中的数据,许多特征变量都是高度相关的。所以实际上大量压缩数据是可能的,而且仍然会保留99%或95%的差异性。
具体实现算法
1.从1开始,依次递增k的值,尝试检查差异性是否达到预设值。
例如:
- 尝试k=1时的PCA。
- 计算出Ureduce,z(1),z(2),…,z(m),x(1)approx,…,x(m)approx
- 检查是否满足:
[(1/m)∑(m,i=1)||xi−x(i)approx||^2]/[(1/m)∑(m,1=m)||x(i)||^2] <= 0.01
如果满足条件,我们就用k=1;但如果不满足,那么我们接下来尝试k=2,然后我们要重新走一遍这整个过程。
以此类推一直试到上面不等式成立为止。
这种方式非常低效。每次尝试使用新的kk值带入计算时,整个计算过程都需要重新执行一遍.
2.一种更快的算法
当你调用svd来计算PCA时,你会得到三个矩阵[U,S,V]:
[U,S,V]=svd(Sigma)
除了之前提到的U矩阵之外,当你对协方差的矩阵Sigma调用svd时,我没还会得到中间的这个S矩阵。S矩阵是一个n×n的对角矩阵,它只有在对角线上的元素不为0,其余的元素都是0。并且显而易见,它是一个方阵:

实际上对于一个给定的k值,可以通过这个SS矩阵方便的计算出差异性那一项的值:
例如,假设差异性要满足小于0.01,那么可以得出:
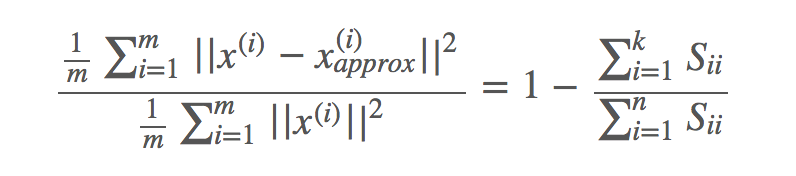
即:
∑(k,i=1) Sii/∑(n,i=1)Sii ≥ 0.99
可以从1开始,慢慢增大kk的值,来计算上面这个不等式,直到满足为止即可(得到满足上面不等式的最小kk值)。
总结:只需要调用一次svd函数,通过svd给出的S矩阵你就可以通过依次增加k值的方式来求解
步骤:
1.对协方差矩阵Sigma调用一次svd:
[U,S,V] = svd(Sigma)
2.使用下面的不等式求得满足条件的最小k值:
∑(k,i=1) Sii/∑(n,i=1)Sii ≥ 0.99
即使你想要手动挑选kk值,如果你想要向别人解释你实现的PCA的性能具体如何,那么一个好方法就是算出这个值:∑(k,i=1) Sii/∑(n,i=1)Sii。它会告诉你百分之多少的差异性被保留了下来。
PCA应用场景总结
1.数据压缩
- 减少内存或者磁盘空间的使用
- 提升学习算法的效率(k值的选择是关键)
2.数据可视化
- 将数据降维到二/三维度进行可视化展示
通过PCA来提高学习算法的速度
举例说明,假如你正在用机器学习来处理图片数据。假设每张输入的图片尺寸是100×100100×100的,那么对于每张图片来说,都有10000个像素点。假设样本x(i)是包含了10000像素强度值的特征向量,即:
x(i)∈R
那么对于我们的样本数据集来说:
(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))
每个样本中,对应的x(i)都是10000维的特征向量。
可想而知,这么高维度的数据带入到逻辑回归、神经网络、支持向量机或者任何别的算法中,学习算法运行的都会很慢。
幸运的是,通过使用PCA,我们能够降低数据的维数,从而使得算法能够更加高效地运行。这就是PCA提高算法运算效率的原理。
降维步骤
首先我们需要检查带标签的训练数据集,并提取出输入数据。我们只需要提取出x并暂时把y放在一边。这一步我们会得到一组无标签的训练集:
x(1),x(2),…,x(m)∈R10000
从x(1)到x(m),每个样本都是10000维的数据。然后我们应用PCA降维,我们会得到一个降维后的1000维的数据集:
z(1),z(2),…,z(m)∈R1000
这样我们就得到了一个新的训练集:
(z(1),y(1)),(z(2),y(2)),…,(z(m),y(m))
现在,我可以将这个已经降维的数据集输入到学习算法中,来得出假设函数,并把降维后的数据作为输入带入,做出预测。
以逻辑回归为例:
逻辑回归中,我们得到的假设函数如下:
hθ(z)=1/[1+e^(−θTz)]
我们将z向量作为输入带入,并得出一个预测值。
最后,如果你有一个新的样本x,那么你所要做的是将你的测试样本x通过同样的PCA降维之后,你会得到这个样本所对应的z。然后将这个z值带入到这个假设函数中进行预测。
PCA的错误使用—使用它来避免过拟合
有一个值得提醒的频繁被误用的PCA应用场景,那就是使用它来避免过拟合。
具体原因是将高维度数据降维处理后,相较于原先的数据,会更不容易出现过拟合的现象。例如我们将10000维的数据降到了1000维,那么降维后的1000维数据相较于降维前的10000维数据更不容易产生过拟合。
因此有人认为PCA是一种避免过拟合的方法,需要强调一下,为了解决过拟合问题而使用PCA是不适合的.
如果你比较担心过拟合问题,那么你应该使用正则化方法,而不是使用PCA来对数据进行降维。
PCA会丢失信息:如果你仔细想想PCA的工作原理,你会发现它并不需要使用数据的标签,你只需要设定好输入数据x(i),同时使用这个方法来寻找更低维度的数据近似,在这个过程中,PCA实际上已经把某些信息舍弃掉了。
两个建议
1.真的需要PCA吗?
2.不要一开始就带入PCA:先使用原始数据x(i)看看效果
