Abstract:TTS是文字转语音。实现原理是从文本中攫取足量信息用于语音合成,再生成波形。主要方法有:拼接法,参数法,混合法和神经网络端到端学习。
核心概念
ASR(Automatic Speech Recognition):语音转文字;
TTS(Text-T0-Speech):文字转声音,如siri.
TTS: 实现人机语音交互,建立一个有听和讲能力的交互系统所必需的关键技术;是将计算机自己产生的、或外部输入的文字信息转变为可以听得懂的、流利的口语输出的技术。
实现方法
输入是文本,输出是波形(waveform)。
1.从文本中攫取足量信息用于语音合成:一套语言学标注系统,分词——文本转换为单词串成的句子——给句子标注音素级别(上一个音素/下一个音素)、音节级别(单词的第几个音节)、单词级别(词性/在句子中的位置)等对语音合成有帮助的信息。
2.生成波形:有2种思路;一种是拼接法(做语音库,再从库中找合适的speech unit拼接);另一种是做语音库,用统计模型学习到每个音到底怎么发的,再根据学出的特征复原。
语音库:是大量文本和其对应音频的 pairs。为实现更精细的语音合成,需要用语音学标注系统自动标注一遍文本,再用类似语音识别的工具得到音素和音频时间上的区分,即得语音库里的每个音素在音频的起止时间(即音素本身的waveform)以及对应的语言学标注。
TTS语音合成技术的主流方法流程解析:
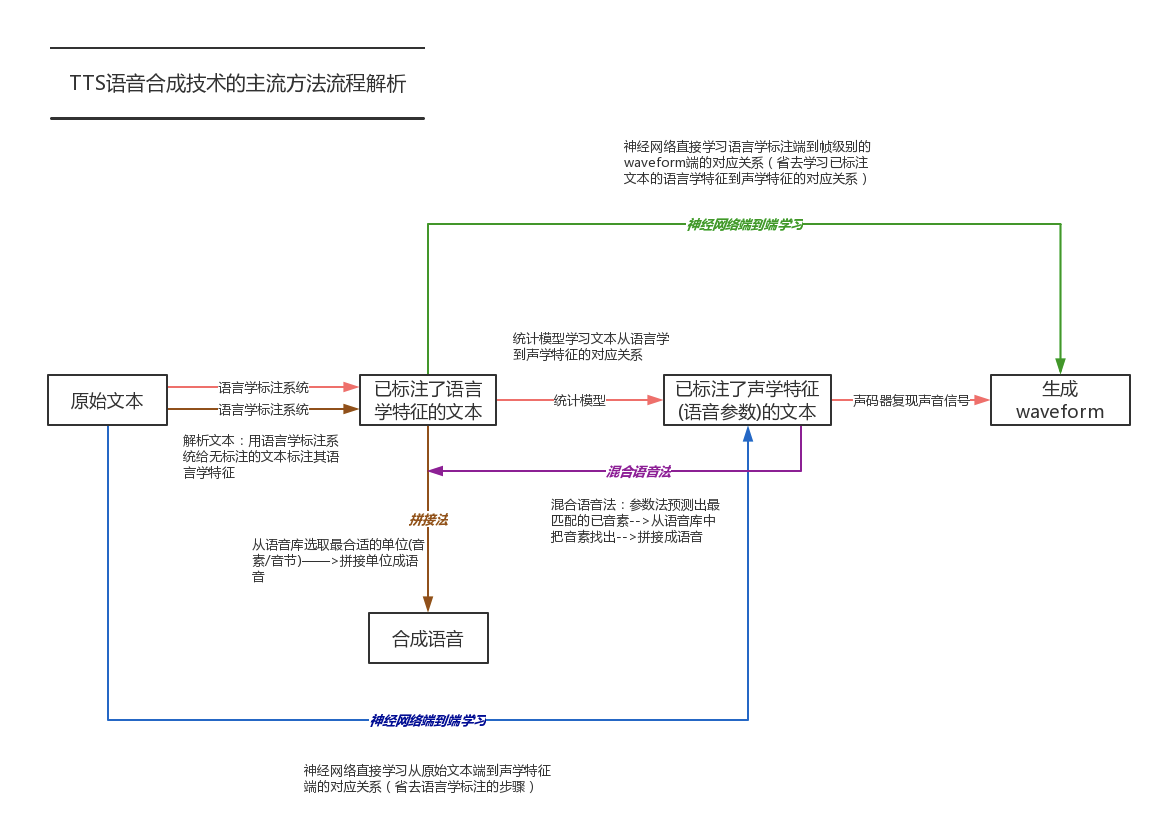
A.拼接法
定义:用语言学标注系统跑一遍输入文本,得到一串语言学标注。然后从中选取所需的基本单位拼接而成(单位最好在语言学和声学特征上都类似)。单位可以是音节、音素等。为追求合成语音的连贯性,也常使用双音子从一个音素的中央到下一个音素的中央)作为单位。
音节:音位组合构成的最小的语音结构单位。如汉语中一个汉字一般一个音节,每个音节由声母、韵母两个部分组成[1] 。汉语普通话中的无调音节(不做音调区分)共有400个音节。在英语中一个元音音素(音素不是字母;a e i o u共五个)可构成一个音节,一个元音音素和一个或几个辅音音素结合也可以构成一个音节。
音素:phoneme,是语音中的最小的单位,分为元音、辅音两大类。如汉语音节 ā(啊)只有一个音素,ài(爱)有两个音素,dāi(呆)有三个音素等。英语国际音标共有48个音素,其中元音音素20个、辅音音素28个。
严格来说没有声码器部分;或者说其声码器就是直接选取原声片段信息。
优点:语音质量较高,听起来比较自然。
缺点:
- 数据库要求太大,需要保存大量原音信息(一般需要几十个小时的成品语料)。企业级商用的话,需要至少5万句,费用成本在几百万元。
- 若库里音素切分出错、语言学标注出错,则最后合成的语音发音也会出错。
B.参数法
1)定义:文本抽象成语音学特征,再根据统计模型学习出从语音学特征到其声学特征的对应关系,再从预测出的声学特征还原成waveform的过程。//或者说,根据统计模型来产生每时每刻的语音参数(包括基频、共振峰频率等),然后把这些参数转化为波形。主要分为3个模块:前端处理、建模和声码器。
核心:是个预测问题,即根据学习得的东西预测出声学特征,然后还原成波形;目前主流是用神经网络来预测。
统计模型学习:用统计模型学习每个音到底怎样发,再根据学出的特征复原声音。
基频:指一个复音中基音的频率。在构成一个复音的若干个音中, 基音的频率最低, 强度最大。 基频的高低决定一个音的高低。 平常所谓语音的频率, 就是指基音的频率
共振峰频率:元音和响辅音声谱包络曲线上的峰巅位置。共振峰的本义是指声腔的共鸣频率。
前端:解析文本,决定每个字的发音是什么,这句话用什么样的语气语调,用什么样的节奏来读,哪些地方是需要强调的重点,等等。常见的语气相关的数据描述包含但不限于下面这些:韵律边界,重音,边界调,甚至情感。
声码器:作用是复现声音信号,难在重现声音细节,且让人听不出各种杂音、沉闷、机械感等。目前常见的声码器都是对声音信号本身作各种理论模型及简化假设,而对细节的描述近似于忽略。 声码器是目前主流语音合成系统的一个核心竞争力,因为最终声音好坏与之有直接关系。
注:拼接法和参数法,都有前端模块,拼接和参数的区别主要是后端声学建模方法的区别。
2)优点:数据库要求相对较小。
- 若只需出声(做demo),大概500句即可,但效果不行;
- 通用TTS一般需要至少5000句,6个小时(一般录制800句话,需要1个小时);
从前期的准备、找人、找录音场地、录制、数据筛选、标注,最终成为“可以用的数据”,可能至少需要3个月。
- 个性化TTS:大多用“参数”法
3)缺点:质量比拼接法差一些(主要由于输出的是声码器合成的声音,而声码器忽略对细节的描述,有损失)。
deepmind提出的wavenet:前端无改进,无声码器,相当于把建模和声码器二合一,通过建模手段直接输出声信号。其质量提高的原因在于:直接对语音样本进行预测,不依赖任何发音理论模型,使最后出来的音质细节十分丰富,基本达到与原始语音类似的音质水准。
今年开始火起来的end-to-end的TTS建模方法,加上wavenent的声码器思想,才是未来TTS的发展方向。
C.混合语音合成解决方案
融合参数法和拼接法二者的长处,用基于参数的语音合成系统预测声学上最匹配的音素后,再从库里把它找出来。
D.神经网络端到端学习
- 1.用神经网络直接学习文本端到声学特征端的对应关系(即省去语言学标注输入文本这一步)
- 2.用神经网络直接学习语言学标注端到帧级别的waveform端的对应关系(即省去学习已标注文本的语言学和声学特征的对应关系,以及声码器复现声音信号的步骤),如wavenet
E.未来:是否能实现直接从纯文本端到帧级别的waveform的对应关系?
瓶颈:若直接从字素到音频,模型可能无法自动修正错误拼写问题,故目前字素-音素-音频是必须的。
More Questions
1.语料库怎么筛选文本才能让语音合成系统效果最好?
2.语料库标注质量怎么保证?
3.选哪种语音单位作为合成的最小单位?
4.语言学标注系统怎么实现?
5.到底要标注几层语言学标注才算足量?
6.对于拼接法,从库里找匹配的音素时,怎样算和目标音素语音学上匹配?怎样才算和目标音素声学上匹配?最后搜索的时候,怎么定义这两方面都最相似?
7.对于参数法,得到语言学标注后,到底需要哪些特征向量?特征向量怎么最优表示?同理,到底需要哪些声学特征向量?怎么最优表示?怎么获得静态声学特征的同时也捕捉动态声学特征?
训练预测模型的时候,用什么神经网络结构比较好?用什么声码器?
Baidu DeepVoice
DeepVoice:实时语音合成神经网络系统(Real-Time Neural Text-to-Speech for Production)
基于传统TTS流程,DeepVoice采用深度神经网络和更简单的词性取代原有的转换方法,则系统可兼容所有数据集、语音文件甚至从未涉猎的领域(最大优势是能实时转换,比wavenet快400倍);系统由5部分组成:
- 用于定位音素边界的分割模型:提出CTC损失(connectionist temporal classification)实现音素边界检测
- 用于字素转音素的转换模型
- 判断音素能持续多久的预测模型
- 基频预测模型
- 音频合成模型
现状:需要借助一个音素模型和音频合成组件,未来希望能实现end-to-end语音合成,无需复杂合成流程和依赖手工设计特征的输入或预训练文本。
TTS的目标
1.可理解性(intelligibility):音频的清晰程度,特别是听者能在多大程度上提取出原有的信息;
2.自然感(naturalness):追求的是与可理解性相对的层面,即听者听懂句意的程度、全句的风格一致性,还有地域或语言层面的差异程度等。
TTS的评判标准
1.主观测试
A.MOS(Mean Opinion Scores):专家级评测;1-5分,5分最佳。
B.ABX:普通用户评测,让用户来视听两TTS系统,对比优劣。
2.客观测试
A.对合成系统产生的声学参数进行评估,一般是计算欧式距离等(RMSE,LSD)
B.对合成系统工程上的测试:实时率(合成耗时/语音时长),首包响应时间(用户发出请求到用户感知到的第一包到达时间)。
当前技术边界
1.通用TTS
- 用户预期不高,可满足商业化需求,如滴滴,高德,智能音箱,机器人等
- 用户预期高,则很难满足(由于机械感,不能很自然地模拟人声)
2.个性化TTS
效果没通用TTS好
3.情感TTS
- 业界情感合成增多(大概是由于数据变多)
- 学术界有理论储备,但没怎么做好,由于情感TTS很依赖于情感意图识别、情感特征挖掘、情感数据和情感声学技术等,而NLP在这些方面进展缓慢
瓶颈和机会
1.基础技术
end-to-end的TTS建模方法,加上wavenent的声码器思想。
百度的Deep Voice团队(在美国硅谷的AI Lab),实时语音合成神经网络系统(Real-Time Neural Text-to-Speech for Production)据说比 WaveNet 要快 400 倍。
2.数据缺乏
一方面,特别是个性化TTS,需要数据量更大。比如默认男孩声音,要转成女孩,就比较难。另一方面,数据的获取(制作)成本和周期,也是各家在初期的竞争着力点。
3.人才匮乏:不仅没法跟NLP、CV等热门AI人才比,就算跟同样不算热门的ASR比,TTS的人才都还要少一些。
4.产品化难度:
A.由于技术限制,现阶段不可能有非常完美的TTS效果,所以尽量选择用户预期不苛刻的场景,或者在产品体验设计时,管理好用户预期(比如打车软件,郭德纲/林志玲的声音,差不多就行)
B. 选择“参数法”还是“拼接法”,和公司的技术储备、成本、以及产品目标相关。在垂直领域,现有的TTS技术(参数或者拼接)都可以针对产品做得很好。现在行业还没有太好的效果,很大原因是因为产品经理还没有深入介入,有很多细节的坑要踩~未来一定会有惊艳的产品出现。
C. 体验细节设计,和一般互联网产品很不同,比如:
- 文案设计,非常重要;因为在语音交互场景,不能太长,用户没耐心和时间听完的。
- 可以加入背景音乐,掩盖杂音等细节瑕疵。
- 特殊场景,还有有特别的需求,比如远场TTS,和戴耳机场景,还会区别。
- 中英文混合TTS。比如用户想播首英语歌曲,困难在于:所有中文的发音当中,中文和英文合拍念出来是很难的,为什么呢?因为往往录音的人。录中文是一批人,录英文又是一批人。两种语言结合起来,再用机器学习学出来,声音就会变得非常怪。小雅音箱找到了一个能够和中文发音很像的女孩子,录了很多英语的音。
5.商业化压力
- 如果要有足够的市场竞争力,至少需要12个月的时间,2~6人团队,几百万资金投入(1个GPU一年十万,支持并发只有几十个)。并且,大公司的先发优势巨大,小公司必须切细分场景。
- 我个人认为,个性化TTS、情感TTS会在各细分场景得到更大的应用,比如知识付费、明星IP、智能硬件、机器人等。
商业应用:实现人机语音交互
提供语音服务的设备:导航,为视觉障碍者提供语音辅助,智能客服,智能助理
等等
Ouestions:如何使语音合成的声音更自然?
Q:人工智能语音在说中文时的语气感觉上还比较机械,怎样使人工智能语音的语气更自然一些?
A:把语音合成目标分为2级,第一级是发音清晰,第二级是语气自然与否。
- 目前主流TTS都是数据驱动,抑扬顿挫的感觉必须从录音数据中学习,要对语气进行建模,从单纯发音要求到自然要求,对录音数据量的要求一定变高,一定要学习更多数据。
- 语音合成:由简到繁。TTS:输入文本,输出语音,这是一对多的产生式问题(同一段文本有多种表达方式,涉及到上下文、说话对象、情绪、场景等)
- 数据训练(更自然需要训练更多数据):训练时需要先对数据进行更加细致的描述;数据标注要把发音中的不同语气现象描述出来,然后再给模型训练算法进行学习。常见的语气相关的数据描述包含:韵律边界、重音、边界调、情感等。
- 语音合成时需预测:从文字中把数据描述信息预测出来。告诉AI用哪种表达方式读,然后才用模型生成对应语音;预测不准确常是合成不自然现象的首要原因。
- 扩充式积累数据,自然进化:数据积累很慢,故常让录音的语气逐步扩充。先选择产品最通用的语气情感,再逐步放开限定范围,增加相应变化。
- end-to-end TTS:将数据描述的学习过程直接从未标注数据中心学习到(非监督学习);一旦放松对数据的依赖,数据量的增加会非常快,合成性能也能有本质性的提升。
- 母语比外语更难提高语气自然度:复杂语言,词语句子的歧义性,话中有话等。
